This previous month for Gnuxie & Draupnir, January 2024.
Table of Contents
Introduction
I stole this idea from someone, I can't remember who1 but I thought it'd be a good idea to create a monthly blog post for Draupnir. It gives us a few benefits, we can be more transparent about what is being worked on and what progress is being made, and also it gives me something to look back on so I can also feel better (or worse!) about the work I'm doing. It'll probably help planning in general too and possibly improve documentation and software archaeology in the future.
I'm also struggling with choosing which way to refer to Draupnir and Mjolnir in plural, including by just reusing the singular noun. Great.
Project Status
So, if you're a regular within our support room #draupnir:matrix.org or you've read our most recent
TWIM entry2, then you will already know that work is currently being done on the
matrix-protection-suite abbreviated as MPS. Previously I have stated that I anticipated that work
to be done by the end of 2023 or the start of 2024. Technically it is still the start of 2024,
so we're not breaking expectation yet, but now that we have the PR open a more realistic release
would be March or April. Why is it being pushed back? Well currently the diff for Draupnir's MPS
branch stands at +4,283 −8,771 and I haven't actually deployed it yet3. Draupnir has just over
8k lines of actual code4, meaning that we have so far rewritten somewhere between a quarter and
a half of the entire code base. Given this metric, taking some more time might not be such a bad thing.
I still maintain that I, as a person doing this work, might crash and burn yet before we hit the first milestone: a release of Draupnir that depends upon the matrix-protection-suite. If you or your community use Draupnir, and you want to support me, you should checkout my GitHub sponsors page and Ko-Fi.
Project Meta
Triaging
With the prospect of Draupnir MPS unblocking development, I wanted to have a good view of all the issues we have open and be confident that I wasn't going to miss something important when choosing what to work on. So we did a little bit of reading on how to do issue triaging. I didn't want to spend too long on this, I just wanted a guide from a trusted authority that would tell us how to do it and what to avoid.
We ended up skim-reading https://apenwarr.ca/log/20171213 and watching the associated talk. Which is fair enough, the post goes into a lot of detail but didn't really give me a plan of what to do. So I had a look at the place where the speaker worked, Tailscale, found their issue where they discussed how to triage, and found that they linked to this post https://lostgarden.home.blog/2008/05/20/improving-bug-triage-with-user-pain/. So I basically copied the model they use and adapted it so it would work for me and Draupnir. The way it works is simple: you have a rating for likelihood, annoyance (priority), and impact (which we have invented instead of issue type).
Likelihood is just an estimation of the proportion of users that are likely to come across the issue, with a range from one to five.
Annoyance is how annoying the issue is. This is a range from one to three and we avoid passive-aggressive labelling, for example labelling of an issue as "tolerable" is renown for frustrating issue reporters. When an issue is the most annoying, outrageous, the user is at risk of no longer wanting to use or engage with Draupnir altogether. This is independent of whether the user is technically able to continue. There is a reserved fourth level for something that blocks all development, for example a CI failure. Most issues are expected to sit around the second level, aggravating.
Finally there is a categorisation of the issue type, which we call impact. The reason we call this impact and not type, is because this seems to be a shortcoming in the original model. They have a linear score for the issue type label, and put documentation and visual issues at the lower end. From what I can tell, the intention of the scoring is to represent how the issue relates to workflow. The highest score, crash, means that work can't continue or there's other consequences such as data loss. So by calling this label impact instead of type, we are explicitly saying that its purpose is to highlight issues that hinder people's ability to use or continue to use Draupnir. This includes documentation issues that would prevent them from setting up Draupnir or describing how they can use a feature. If a documentation issue means that a new user can't start or use Draupnir, then this will still be tier six, which is named crash, rather than tier two or below. This is extremely important because categorising issues naively by type and then ranking them (as Tailscale and the linked blog posts appear to) would make critical documentation issues seem less important at a glance.
From these three labels, we can get a score for the pain the issue represents by multiplying their values together. I use a script to then get a list of all open issues ordered by the pain score. Which I found to be accurate enough at highlighting which issues should get attention first. Some people have suggested adding scores instead, but this would surely mean each label contributes an unequal amount to the end score depending on how many variants each label has.
Planning
With our newfound powers to list painful issues, I began planning what post-MPS Draupnir development might look like. This would require turning these issues into user stories. I know, the fear is that we could end up with a bureaucratic problem where it is hard to express simple issues as user stories. So to avoid this, we had do it our way. Which is to accept that it's ok to throw important points that can't easily be expressed as a story under the designation of a Task instead. If things get bureaucratic, then it's being done wrong. Either way, the stories are important to ensure that the scope of planned work is clear and that it's clear how exactly the changes relate to the original bug report, issue, or feature request.
I have developed a roadmap out of the issues that are holding the project back the most. Let us know what you think. Of course this isn't set in stone and bug fixes will naturally be tackled as time goes on.
NLnet
With the encouragement and support of the Matrix foundation, I have independently made an application to NLnet NGI Zero Core. I worked really hard to get this application sent out before the February deadline so that I'd get some feedback asap, since the process can take time. I'm completely open as to what happens with this application, again I made it primarily to get feedback and securing funding as a direct result would be a bonus. This has been the primary motivation for the planning and triage work described earlier, and I think all the reorganising required by developing the application to NLnet will help us out in the long run. I send a special thank you to Josh Simmons for reviewing my application, and also for bringing so much positivity and hope to the Matrix community since the very beginning of his tenureship.
The future
On this note, Cat raised a question in the Matrix Foundation's matrix room about the status of Mjolnir and Draupnir, right as I was rushing to finish my application to NLnet. He asked, slightly cheekily, whether the foundation would declare Mjolnir obsolete and tell people to just use Draupnir instead. I replied with alarm. Clearly Draupnir is a successor project, that currently does get a lot more attention than Mjolnir. And while Draupnir has a strong support community, all of the core development work depends on me.
Originally, I started working on Draupnir because there were improvements sitting dead on the Mjolnir repository that I had been working on that just needed a little push over the line. Similarly, there were ideas such as the ban propagation protection that didn't require much work and improved the user experience in a fundamental way. By the middle of March 2023, I had achieved those things, and while I still maintained Draupnir throughout the year, I was focusing on other things5. This wasn't leaving the project behind, there were still releases and feature development happening in this period, it was just a lot slower. I needed to do something different, maybe even move on.
This came to a close when in late August MTRNord approached me, wanting to setup an instance of the Draupnir appservice in time for the Matrix community summit. I helped with that, even contributing a whole bunch of getting started documentation for the new service. Draupnir and Mjolnir have always felt a little underwhelming, far from achieving their potential. And this feeling is compounded when in context, right after a homeserver, they are essential tools to running a public facing community on Matrix. Even more so, when a community does not and cannot self host.
It should be extremely embarrassing to Matrix advocates, that these tools in their current state are what people have to use and tolerate. If that sentence was unclear: specifically advocates who have previously been responsible for resourcing these projects6.
With that in mind, I decided to turn my attention to what I felt should be done to take Draupnir and Mjolnir to the next level. And this would be looking at the fundamentals that everything else is developed upon. Without a concise, consistent, and expressive core every feature that is developed will inevitably be a crumbling mess. The matrix-protection-suite is my answer to this call.
Developments
In this section I'm going to talk about implementation details of Draupnir and the Matrix protection suite while describing what I've been working on.
Context
To be able to understand some of these developments, you need to understand some context from
prior months, which have gone without a fancy update like the post you are reading.
In the current main branch for Draupnir, there is no Draupnir class.
There is a Mjolnir class, that acts a little bit like a god class, it has lots of non-parameterised
dependencies. Draupnir MPS breaks that class up with the Draupnir class and any remaining
dependencies are explicitly given to the constructor. This comes at a cost of more complicated
setup code, that means there's more code to write to create an instance, because all the dependencies
have to be setup in a similar way from somewhere. However, with this you get the ability to fake or
attenuate any dependent functionality, which is extremely powerful when it comes to changing or
testing the functionality of Draupnir.
If in the following sections I have made an assumption that you understand an essential Matrix concept, then don't fret, please refer to the Draupnir development context document. You can also reach out to me in our support room #draupnir:matrix.org.
Revisions
MPS introduces the concept of a revision, which is a read-only snapshot of a room's state at a given
point in time8. Some revisions are specialised to reflect specific types of state, such as
the policies present in a room, or the membership of a room's users.
Revisions have methods that help introspect this state, such as finding all the policy rules that
match a given entity9. Or query how many user's are currently invited to the room. Revisions do
not strictly need to be tied to a Matrix room either, in MPS a PolicyListRevision can be virtual
and comprised of policies selected from a variety of policy rooms.
Revisions are revised by using an existing revision and combining it with a description of the current room state, and this will create a new revision. The old revision would then be referred to as the previous revision. In MPS revision issuers take the role of providing new revisions as room state changes.
MPS: ClientsInRoomMap
Quite early on in Draupnir's development I decided that ideally we would have access to all room state immediately. Why? Because not only does Draupnir need the room state for checking membership or policies, but other protections can also need the room state for arbitrary reasons. In pre-MPS draupnir, protections had to find this information all on their own, and implement all the code they need to handle state, room membership, or creating a history of the timeline to scan. Typically this is duplicated adhoc across protections, and means that implementing new protections comes with finding that you need a solution to many fundamental problems. Which in turn means protections need more code to implement, and are generally poorer quality, because less time can be spent on working on what the implementer set out to work on.
At the start of the new year I was working on the ClientsInRoomMap, an abstraction for the
matrix-protection-suite that can track which clients an appservice is responsible for are in a room.
Conveniently, this also means that an individual Draupnir and all protections can have one place
to find out which rooms their client is present in, and when we join and leave them.
This is something that was needed by Draupnir4all because currently there is no way to conveniently
link clients to joined rooms and vice-versa.
Crucially this is also important if we want to be able to only inform a Draupnir about the events that
its Matrix client should be able to see, not every event that the appservice can see as a whole.
This was also important for the new room state caching system. Since to be able to update the new
room state cache, an appservice will need to be able to find a client it can use to fetch new
room state, since not every client an appservice can choose from will be in the room10.
As an aside, it's somewhat unfortunate that as an appservice our only way to fetch state is via the
client-server API, and there's no way to have state or state deltas pushed to us by the homeserver.
Draupnir: DraupnirFactory
The Draupnir code base inherited something called the MjonlirManager from Mjolnir4all.
This was appservice specific code for both managing any existing provisioned Mjolnirs that
need to be run, and creating brand new ones for users. Now that the Mjolnir class was being broken
down, this code would be a lot more complicated, and the multiple responsibilities of the
MjolnirManager would become apparent. Given that the setup code for Draupnir was already more
complicated, it made sense to create something called the DraupnirFactory. This is just a factory
that creates Draupnirs for both the appservice and when you just want to run Draupnir as a single bot.
Then, there would be a DraupnirManager focussed on running a collection of Draupnir and
then an AppServiceDraupnirManager which would focus on loading configuration from
persistent storage and asking a DraupnirManager to run those Draupnir for us.
Draupnir: PromptForAccept
Wait what? What does that even mean?
Basically, when you issue the ban command with !draupnir ban @spam:example.org and forget
to give any of the other arguments, Draupnir will prompt you for the missing arguments.
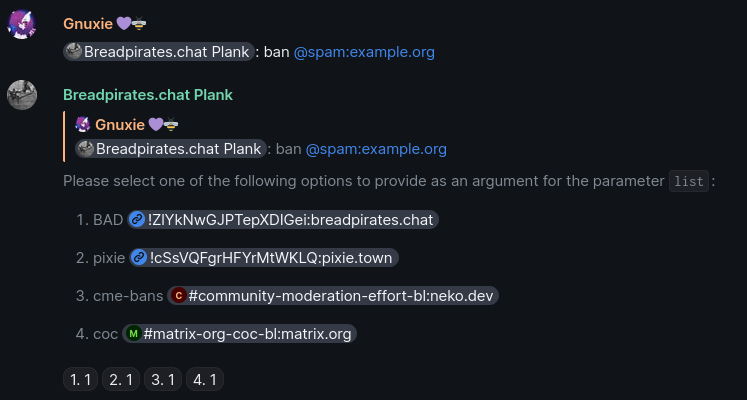
Figure 1: Draupnir prompting for arguments
This used to be done by keeping a continuation with all the call context leading to this point alive while Draupnir waits for your response. As initially is seems quite complex to figure out how to serialize or reference all the necessary context to avoid using a continuation, we never did. As a result, there had to be some limit to how long Draupnir would wait for you to respond or you'd end up with a memory leak. This limit was 10 minutes, and you've probably noticed it.
Fortunately, it was pretty easy to change this since the only context that's needed to get back to
this point is the original command that was given to draupnir !draupnir ban @spam:example.org.
The code was also begging to be revisited because it duplicated the same functionality that was used
for the BanPropagationProtection, which could embed context within the event that it used for
the prompt. And finally, it had to be changed now that the legacy MatrixEmitter was being
removed from the Draupnir code base in the MPS branch, which the continuation for promptForAccept
depended upon. While we were here we also took a look at Draupnir#160 and settled on the number
emoji.
MPS: Declarative test utilities
In hindsight, more unit tests could have been written for MPS sooner, but that will probably always have been the case. Regardless, I wasn't sure yet what unit tests should look like for MPS. I didn't want to add a bunch of tests that I would soon regret the existence of, because they followed a pattern that I'd soon see as flawed, or they had way too complex setup code, or they were just very big and hard to follow. Mjolnir's integration test suite was mostly written by me, and the harness itself was also designed and written by me11. However, this was an integration test suite only because Mjolnir's code was too risky to change, and break down enough to get into unit tests at this point. As a result, a lot of Mjolnir's integration tests, and now Draupnir's do have complex setup code, and do have very imperative long winded ways of describing state. Not only describing state at the start of the tests, but throughout them. Relatively speaking, Mjolnir's tests are probably pretty good compared to some tests I've grappled in Java land, but that's a low comparison and we can do better. So as you can imagine, I didn't want a repeat of Mjolnir's test inertia.
All of MPS's components are interfaced, and all dependencies are expressed through interfaces and
need to be provided explicitly. So we already have a leg up. I started by writing a test for
the new MemberBanSynchronisationProtection that replaces the core functionality for Mjolnir's
member ban policy application behaviour and provides it as a protection, which is mostly synonymous
with module. In order to test this, we'd have to have some way of describing the initial state
of not just a protected room, but also a policy room. Then we'd also probably need to change
the state of one or the other, to represent someone joining a room or a new ban being added.
const { protectedRoomsSet, roomStateManager, policyRoomManager } =
await describeProtectedRoomsSet({
rooms: [
{
membershipDescriptions: [
{
sender: spammerToBanUserID,
membership: Membership.Join,
},
],
},
],
lists: [
{
room: policyRoom,
},
],
});
So I came up with this function, used more like a macro, to describe a ProtectedRoomsSet,
which is what is what an MPS protection belongs to. This is composed out of other macros however,
such as the describeRoom macro, whose description object allows you to describe
membership, policy, or generic room state events in much the same way.
The describeProtectedRoomsSet macro here is also returning fake instances12 of the RoomStateManager
and PolicyRoomManager that we can use later to manipulate the state of any dependants.
For example, we can manipulate the state of the policy room to mimick the issuing of a new policy.
roomStateManager.appendState({
room: policyRoom,
policyDescriptions: [
{ entity: spammerToBanUserID, type: PolicyRuleType.User },
],
});
Then we can use spies to see what happens next!
This is something that I have been wishing for for over two years. It's taken until now to have
all the prerequisites that have made this possible. I couldn't even imagine what this macro would
look like until I started writing the test for the MemberBanSynchronisationProtection.
It was only possible because of the length I've gone to in order to isolate Matrix clients and
other dependencies in this library from the start.
Because everything in MPS is interfaced and provided explicitly, it becomes just a chore to fake real scenarios that we might see in the wild on Matrix, all without talking to a real homeserver. Most software can do this to some degree, but we can do it anywhere and everywhere in the code base, there is no dependency on any Matrix client or architecture (since remember, we have to cater to appservices too) whatsoever.
When I first wrote the tests for MemberBanSynchronisationProtection using these macros I was
euphoric, because it showed that the work I'd put into designing MPS this way had paid off.
Tests can be comprehensive and concise, and I don't have to compromise code quality in them.
It's strange, because what I haven't told you yet is that before the 19th of January we were feeling pretty defeated about finding a way to move forward with the unit tests. It felt like the protections needed too many things to be faked to work conveniently. I went scouring the internet for answers and eventually found the book "Working effectively with legacy code", by Michael C. Feathers. This book helped immediately, I haven't read the entire book but just following through the first few chapters has given me the terminology and context to find out what I need. I wish I had this book to hand years ago. It took about three days to go from feeling defeated to having finished my declarative room state API.
MPS: StateTrackingMeta & TrackedStateEvent
When the RoomStateRevision and RoomStateRevisionIssuer interfaces were designed,
we wanted the consumer to be able to decide which state events they would be informed about
and which state events would be stored in whole within each revision.
This was done using a StateTrackingMeta configuration object, which categorised state types into
stored and inform (missing types would be ignored). For the changes to state events of the
inform type to be calculated, we would need to store a minimal version of the state event and
this is what the TrackedStateEvent was. A minimal interface that would allow us to work out
whether an event had been modified or redacted.
export interface TrackedStateEvent {
event_id: StringEventID;
type: string;
state_key: string;
content_keys: number;
}
The reason for having such an interface was so that, we wouldn't need to waste space on keeping
the original source events around in memory in the situation where the consumer was immediately
going to parse the matrix event into something entirely different. An example of this would be
policy rules, since those are usually parsed into an instance of a specialized class, which is used
to create the PolicyRoomRevision. However, given that most state in a room is almost certainly
going to be from room membership, and most of the fields that compose a membership event would be
preserved anyways, it wasn't clear what benefit we were getting from restricting revisions to
containing TrackedStateEvent objects. By my calculations, it didn't really seem like caching room
state in these revisions was costing us enough to be this worried and engineered specifically for.
The cost of having this interface was that all revision types that depended upon a RoomStateRevision
to construct, such as the RoomMembershipRevision or the PolicyRoomRevision, would have to be
constructed incrementally via a RoomStateRevisionIssuer. Even then we would need every single
revision relating to a room since MPS started tracking that room.
Which did work for Draupnir, but might not work for everyone and it was beginning to obstruct
testing, where we needed to use revisions because we had no other fake equivalent of a room.
In MPS issue #6 (linked earlier) I reason that the space saving from this optimization was going to be linear and wouldn't by itself avoid the issues that protecting a room with say a million Matrix users might cause. Though I'm not going to speculate what issues those might be, I think everyone can imagine. By that point, the ecosystem would probably have to undergo an architecture shift as a whole.
So in short, a RoomStateRevision will now preserve the source event and all room state.
Even if someone needed to only have a revision of certain state types, they could engineer
that themselves very easily using the interfaces provided, they don't need it baked in.
MPS: PolicyScope
I had totally forgotten that this existed, but it made sense to me why it does exist.
A PolicyScope refers to the combination of PolicyRuleType and Recommendation. That is an event
type such as m.policy.rule.user, and the recommendation of that policy, usually m.ban.
It's useful to group policies by their scope because that is how policies are searched for.
For example, when we want to test whether @spammer:example.com has a matching ban recommendation,
we would need to search for all policies in the scope m.policy.rule.user & m.ban.
If we've already grouped policies by scope, we can skip that step.
For this specific use case, the grouping can be taken a step further. Policy rules can be split into
two kinds. Literal rules, which are rules that match against an exact user, for example
@spam:example.com. And glob rules, which match using a glob such as @*:evil.example.com.
In MPS we take the liberty of then putting literal rules into a table, where we can just lookup
all the rules sharing the same literal once. Scanning against all glob rules can then be done
separately, if necessary.
Creating these scopes is quite complex. The time that we save for the consumers of
any PolicyRuleRevision is paid upfront when any revision is revised. Though this upfront cost is felt
more in code complexity than actual runtime performance. It turns out, that I never wrote the
code to do so! I had simply written code to copy any existing scope associated with the previous
revision, and it seems that at a glance such code can pass as doing the job.
So I had to write the code to do that.
Closing
That's it for January, this was a really big update that took a lot of editing13. I think for next month's update I need to work on the post as I go along. To create this post I had to scour my journal entries and match them up with commit logs. It's already February the sixth, and I haven't started writing this months post yet, so we'll see.
If you read all of this then you should join #draupnir:matrix.org if you haven't already, since I doubt there will be many people who are this interested in Draupnir and it would be good to talk to you.
Thanks to everyone and see you in the next update.
Footnotes:
I'm pretty sure it was while following a conversation in #foundation-office:matrix.org where Josh posted someone's blog.
As of the 4th of February, I have successfully deployed and run Draupnir MPS. Things don't quite work how they should yet but we're getting there. It can sit and sync just fine though.
According to the tool https://github.com/AlDanial/cloc.
Maybe I could talk about that in a future update.
Granted, it is embarrassing for many advocates, but seemingly not embarrassing enough. It has been the foundation's own assessment that Mjolnir lies in maintenance mode. Speaking very honestly, I have been ashamed to be associated with Mjolnir at points. There are still issues in Draupnir that come up now and again that feel so embarrassing, to the bone. Of course, there's always context to explain why the projects are quirky, but it's terrible that a project which is the first and only line of defence for much of the ecosystem is in this state. I personally will be hurt if this is attempted to be explained away with an appeal to the funding constraints that have presented themselves presently, because it is blatently obvious that other prioritisations have been made, throughout the foundation's history, and continue to be. However, I want to stress to you that it is essential that the foundation be supported in its quest to become independent of Element, throughout its structure7.
On a personal note, there is so much I want to say, but I've already focused too much on what the powers at be might say in defence or otherwise. I've already probably undermined my own points to make sure that they can't be exploited by them in some obscure way.
Subjectively, from our homeserver's perspective.
An entity can be any Matrix concept, for example a Matrix user, a Matrix homeserver, a room, even an event.
I'm certain that there is a utility for tracking state, and maybe there are more for some of these other responsibilities within the matrix-appservice-bridge library (or something similar enough). However, from what I can tell, this doesn't do quite what we want it to. We also need to remember that MPS is supposed to work with any Matrix backend. For Draupnir at least, we also need an answer for the bot version of Draupnir, which remains the main way people deploy Draupnir. In hindsight we probably should have attempted to use them in the implementation of our interfaces.
Though, Mjolnir and Draupnir depend on a tool called mx-tester. This is a project that was championed by my former senior Yoric. Element didn't have an answer for the use case we had. Not only did we need a tool for spinning up Synapse in both development environments and CI systems (which I believe homerunner could be capable of) but we also needed to do that while modifying the Synapse modules dynamically. Since Mjolnir (and other tools we worked on internally) had Synapse modules that needed to be tested too. It's a testament to the pain Yoric endured making this tool that it still works, though I don't know what I am going to do when it eventually breaks. I'm hoping that homerunner is in a better situation and that surely the rest of Element has similar integration tests by this point, right? It could already be silently broken given Element forked Synapse and probably changed the docker registry etc. But maybe that's also a good thing since a future breaking change in Synapse won't cause it to fall. I did work on this tool initially, since I was the one who needed it most, but eventually the complexities of Docker got too demoralising and I had to hand my work over. I'm pretty sure just working on this tool contributed to a lot of fatigue on the team, given we were a team of just three, and having to develop a tool that should have been central to a company, at that time, of over 120 developers.
For those unfamiliar with unit testing terminology, a Fake is an object that has complete functionality, it just doesn't depend on any resources such as file descriptors, databases, or in our case a matrix client that talks to a homeserver.
I'd also like to thank Bea for reading the drafts, editing, advising, and suggesting changes.